瞎搞的原因
测试过程中使用BurpSuite的Intruder模块进行攻击后,由于测试的payload较多,并且Response返回值通常包含了HTTP响应头以及响应主体,如果需要手动从成百上千个文件中提取出想要的数据,会比较麻烦,所以就自己写了一个脚本,用于获取Response中指定的文本内容。
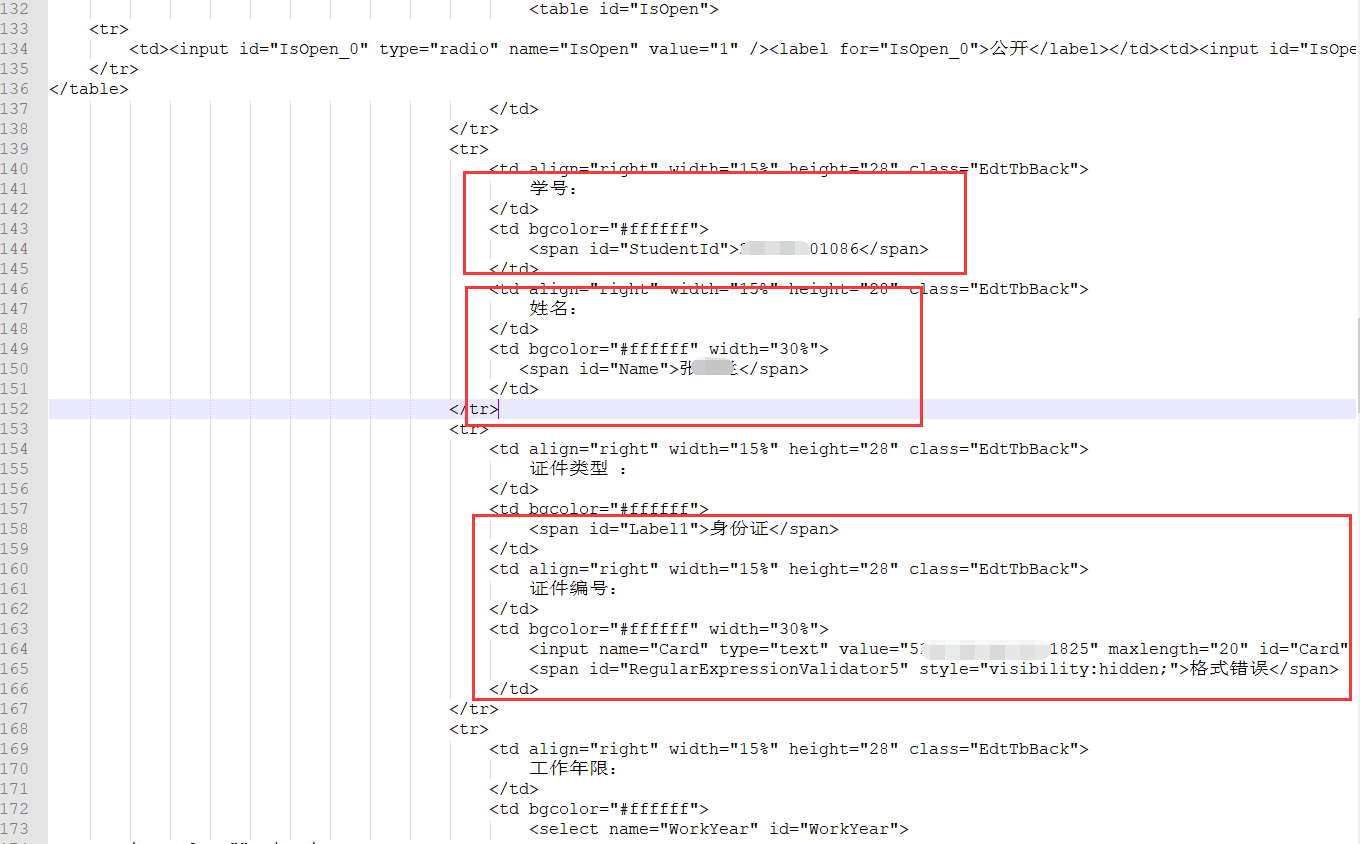
样例
为了提取Response中的学号,姓名等数据,所以才写了这个小脚本。一边百度一边写的。
代码
python3
# * coding:utf-8 *
import re
import os
def output(name,id,idCard):
'''用于接受想要提取的值并进行输出'''
for i in name:
'''获取姓名'''
pass
for j in id:
'''获取学号'''
pass
for k in idCard:
'''获取身份证'''
pass
result = i+"\t\t\t\t"+j+"\t\t\t\t"+k+"\n"
print(result)
'''将读取的结果写入到指定的文件之中'''
writeFile = open("D:\\test.txt","a+") //将结果写入的文件路径
writeFile.write(result)
filePath = "E:\\Test" //你的路径
os.chdir(filePath)
fileName = os.listdir()
print("姓名\t\t\t\t学号\t\t\t\t身份证")
for getFile in fileName:
'''获取目录下所有文件的名字,后续逐个打开提取数值'''
with open(getFile,'r') as strf:
str = strf.read()
getName = r'(?<=<span id="Name">).*?(?=</span>)' //将<span id="Name">替换成要获取数值的标签,后面的也是一样,照葫芦画瓢完成。
getId = r'(?<=<span id="StudentId">).*?(?=</span>)'
getIdCard = r'(?<=<input name="Card" type="text" value=").*?(?=" maxlength="20" id="Card" />)'
id = re.findall(getId,str)
name = re.findall(getName,str)
idCard = re.findall(getIdCard,str)
if (id,name,idCard) != "":
'''如果读取的值不为空,则调用函数对内容进行输出'''
try:
output(name,id,idCard)
writeFile.close()
except:
'''如果Response中的想要的值为空,则跳过处理'''
pass结果
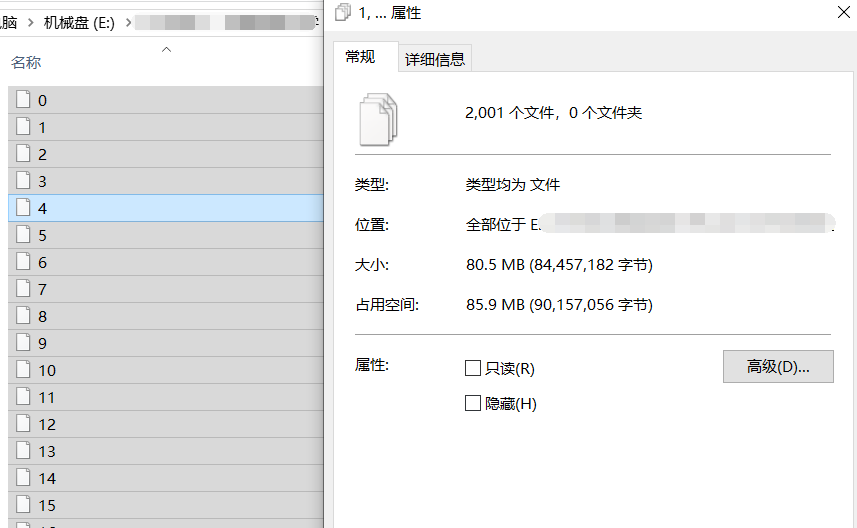
从2001个文件中提取出了自己想要的内容。

有些不足,但是还是能用,才开始学没多久,也有很多需要改进的地方。